

Amazon Textract is a service that automatically extracts text and data from scanned documents that goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables. Many companies today collect data from scanned documents such as PDFs, tables, and forms, through manual data entry which is slow, expensive and prone to errors. The Textract service makes it easy for customers to accurately process millions of document pages in just a few hours, significantly lowering document processing costs, and allowing customers to focus on deriving business value from their text and data instead of wasting time and effort on post-processing. Integrating your FileMaker application with Textract can allow you to quickly and easily leverage the power of AWS machine learning to turn paper or scanned documents into useful, digital information.

How to Get Started
In order to begin connecting your FileMaker database to work with AWS Textract, you will first need to have an active AWS account and set up an IAM user. Amazon has a great walkthrough on setting up these profiles, and be sure to capture the Secret Key and Access Key for your user.
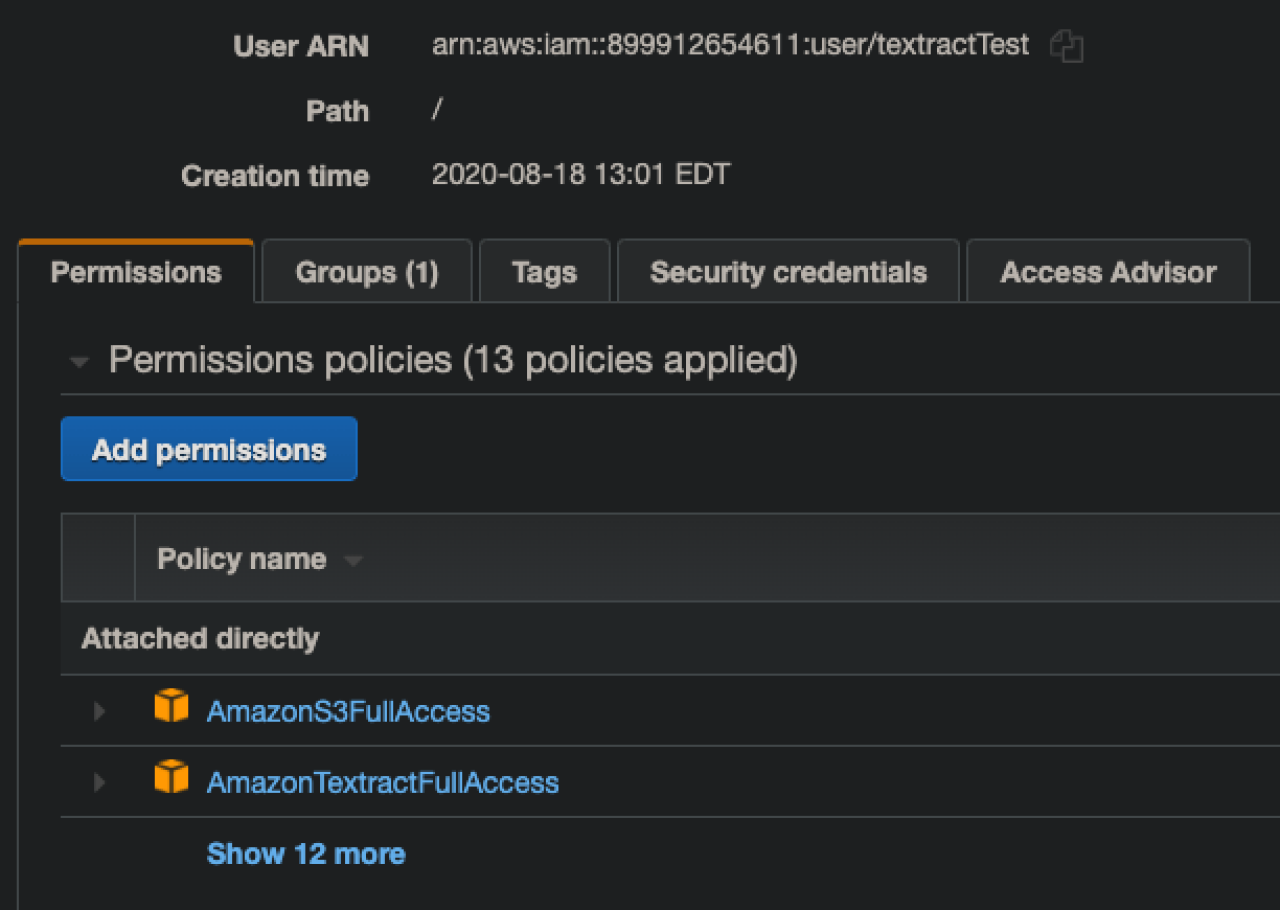
You will also want to be sure you have added full access permission for Amazon S3 where our documents for processing will be stored, as well as full access permissions for Textract. Once your user is created, you will also want to navigate to the S3 service and create a new storage bucket that your user has full access to. Capture the name and region of your new bucket, and you'll want to store that along with your users keys in your FileMaker database in order to connect.Please note that Textract does not need to be explicitly enabled on your AWS account and has no minimum fees, but is a paid service that charges around 5 cents per page processed. There are free tier options that may apply to your account, so feel free to explore those in your AWS management console.
Uploading your Document
Once you have the information from your AWS, choose a document that you want to process and store it in a container field in your FileMaker database. You will want to use an image or a PDF, and I would suggest starting with something such as a simple table or form to get an understanding of how data is processed and returned by Textract.
In order to process your document, you want to store it in the S3 bucket we created previously.

This is done by delivering a hash of the data along with a signature including your user keys via cURL to the Amazon S3 host, and specifying the bucket and region to store it in. Note that there is not a session token authentication process as you might see with many other integrations, but instead each request that is delivered to AWS includes a signature containing your specific user key information. A great example on building AWS cURL requests that is widely used throughout the FileMaker community is included with the demo you can download below.
Running the Textract Analysis
Now that your document has been uploaded and stored in an S3 bucket, the next step is simply telling AWS to trigger the Textract Document Analysis job. This is again done by delivering a cURL request including your user signature to the AWS host, but this time specifying the Textract service and pointing to the document that you want it to process. Once the job has been successfully initiated, AWS will return a Job ID that you want to store as a reference to the Textract process you just started and the data it will produce. Depending on the size and complexity of the document you uploading, the analysis process can take anywhere from a second or two to well over a minute.
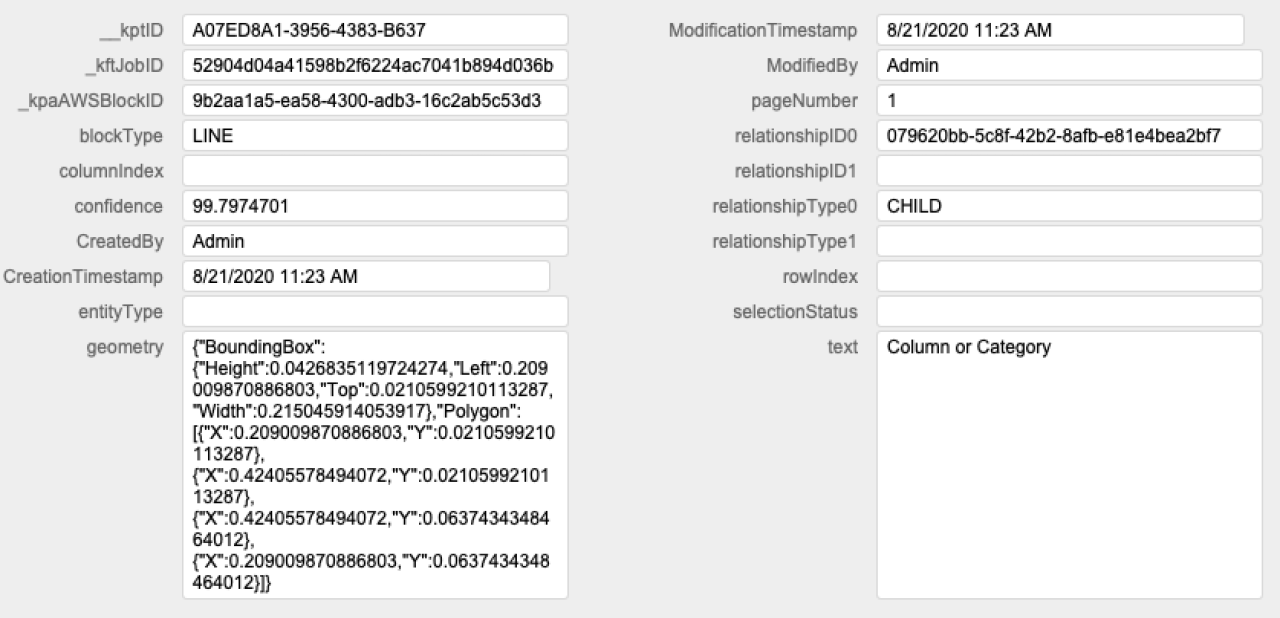
There are a couple of ways to identify when the process is completed, but the simplest is to just request a status update from AWS. By providing the Job ID in another cURL request to the Textract host, you can check to see if the status of the job is either "IN_PROGRESS" or "SUCCEEDED". Once the analysis is complete, along with the successful job status the response will also include "BLOCK" data. This is the information we are after, and will be a large volume of JSON data indicating the type, position, and content of each recognized element in our document along with its relationship to other elements.
Processing your Block Data
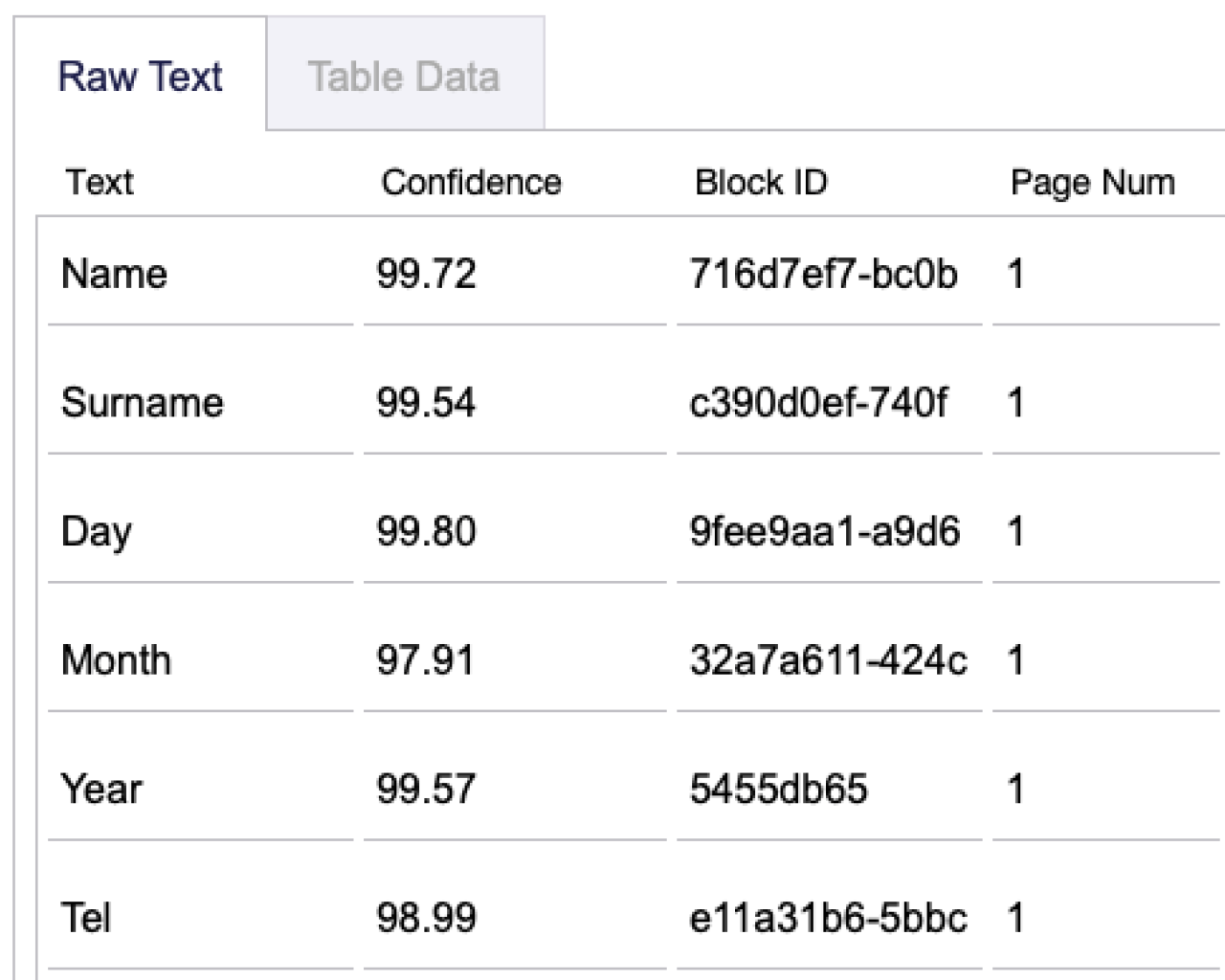
The Textract process will generally return information about your document in three different types; raw text, table content, and form data (also known as key-value pairs). The best way to turn this into something we can use in FileMaker is by looping through the significant volume of JSON text and creating a record in a separate BLOCK table for each element. Here you can store the content, type, location, and relationship information about each element, and then we can use simple relationships to link together parent and child elements. This will provide a much more useful way to either present to a user the analyzed information, or to parse the data we care about into the relevant FileMaker fields.
Conclusion
Integrating Amazon's Textract service with FileMaker can be an excellent, low cost option for going beyond 3rd party OCR options and pulling the relevant information from images or PDFs directly into your solution. With all the processing done automatically, you can eliminate double data entry and provide useful reports and analysis much more quickly. Contact us if you would like help integrating Amazon Textract into your FileMaker application!
Did you know we are an authorized reseller for Claris FileMaker Licensing?
Contact us to discuss upgrading your Claris FileMaker software.
Download the DB Services - FileMaker Amazon Textract Integration File
Please complete the form below to download your FREE FileMaker file.



